Sobre mim
Engenheira de Dados. Curiosa por natureza.
 <
<Comecei como estagiária em 2021, desenvolvendo meus primeiros scrapers e pipelines, e hoje atuo como engenheira de dados, evoluindo continuamente com stacks modernas do ecossistema. Sou formada em Ciências Econômicas, o que me ajuda a olhar para dados além da técnica e estruturar melhor problemas antes de propor soluções.
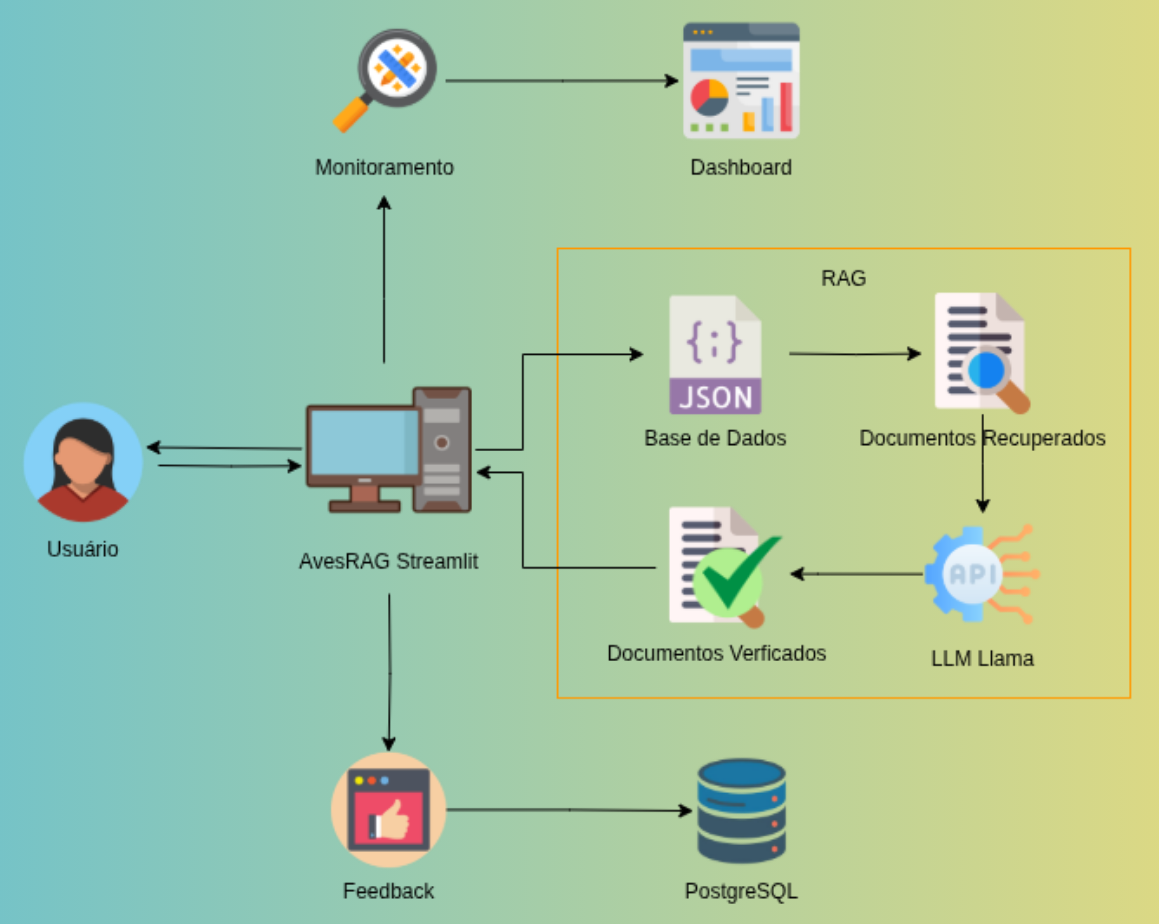
Fora do trabalho, sou movida por curiosidade. Desenvolvo um projeto pessoal de catalogação de aves em Uberlândia, organizando características morfológicas e comportamentais e expandindo para uma base nacional e, futuramente, global. Já criei um assistente com RAG e LLMs para identificação de espécies a partir de descrições textuais.
Também ensino matemática para crianças e, durante a graduação, trabalhei com artesanato em papel, produzindo cadernos e restaurando livros — algo que ainda mantenho como hobby.
Sou leitora de ficção científica, especialmente Androides Sonham com Ovelhas Elétricas?, de Philip K. Dick, que me interessa pelas reflexões sobre consciência e identidade.
Perfil Técnico
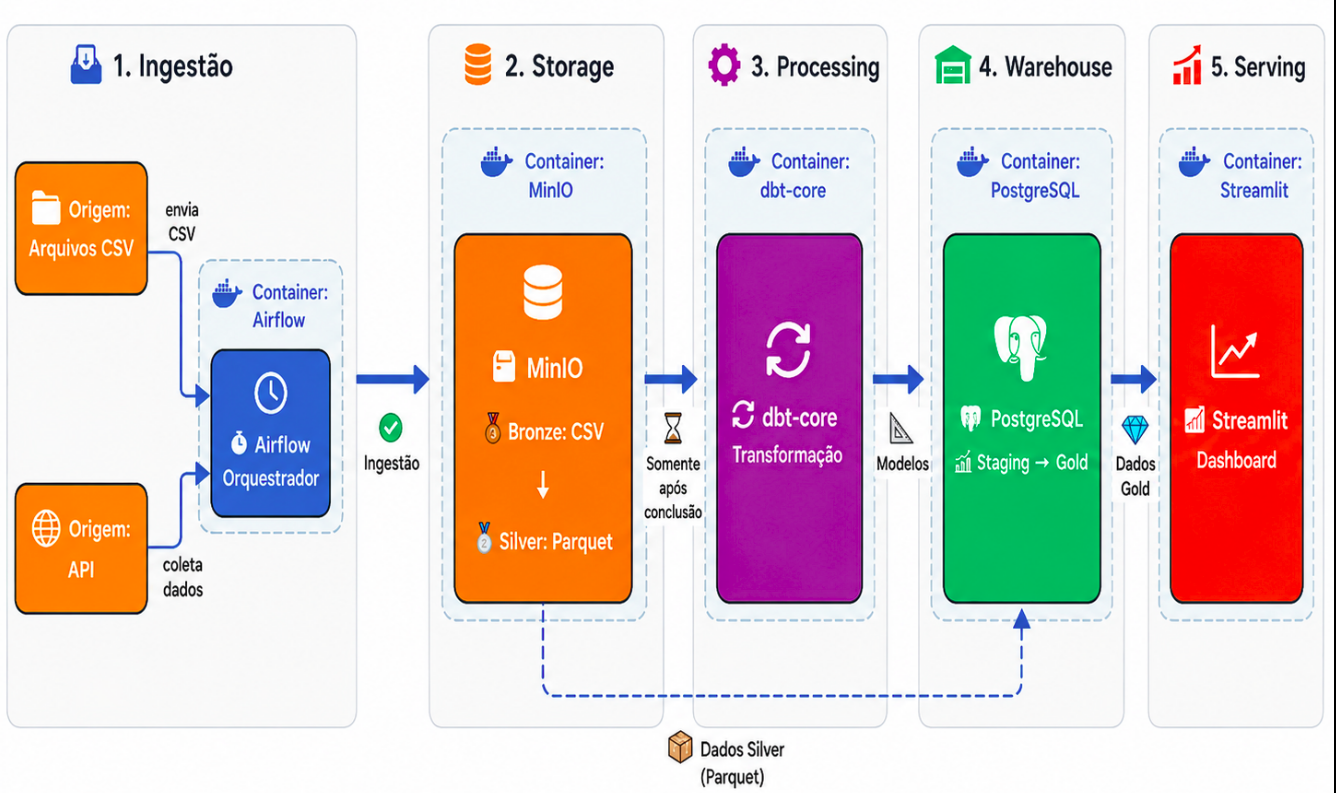
Atuo há mais de 3 anos com engenharia de dados, construindo e operando pipelines em produção de ponta a ponta — desde a coleta de dados via APIs públicas e web scraping até a modelagem, armazenamento e disponibilização para sistemas e áreas de negócio.
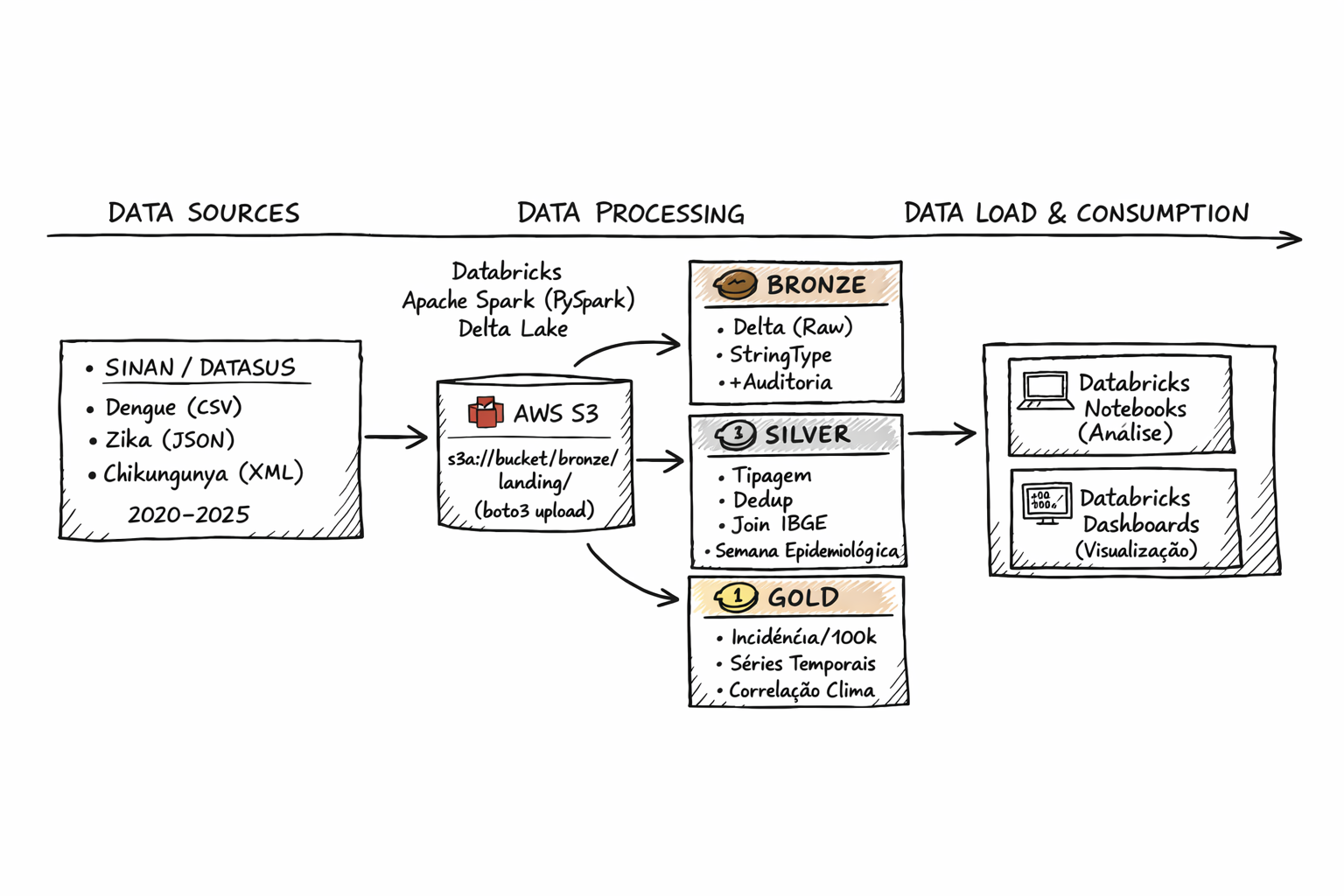
Nesse período, trabalhei com dados em larga escala, em pipelines que vão desde o processamento de bases com centenas de milhões de registros históricos até fluxos contínuos de eventos em sistemas de produção, em contextos como marketplaces e dados jurídicos.
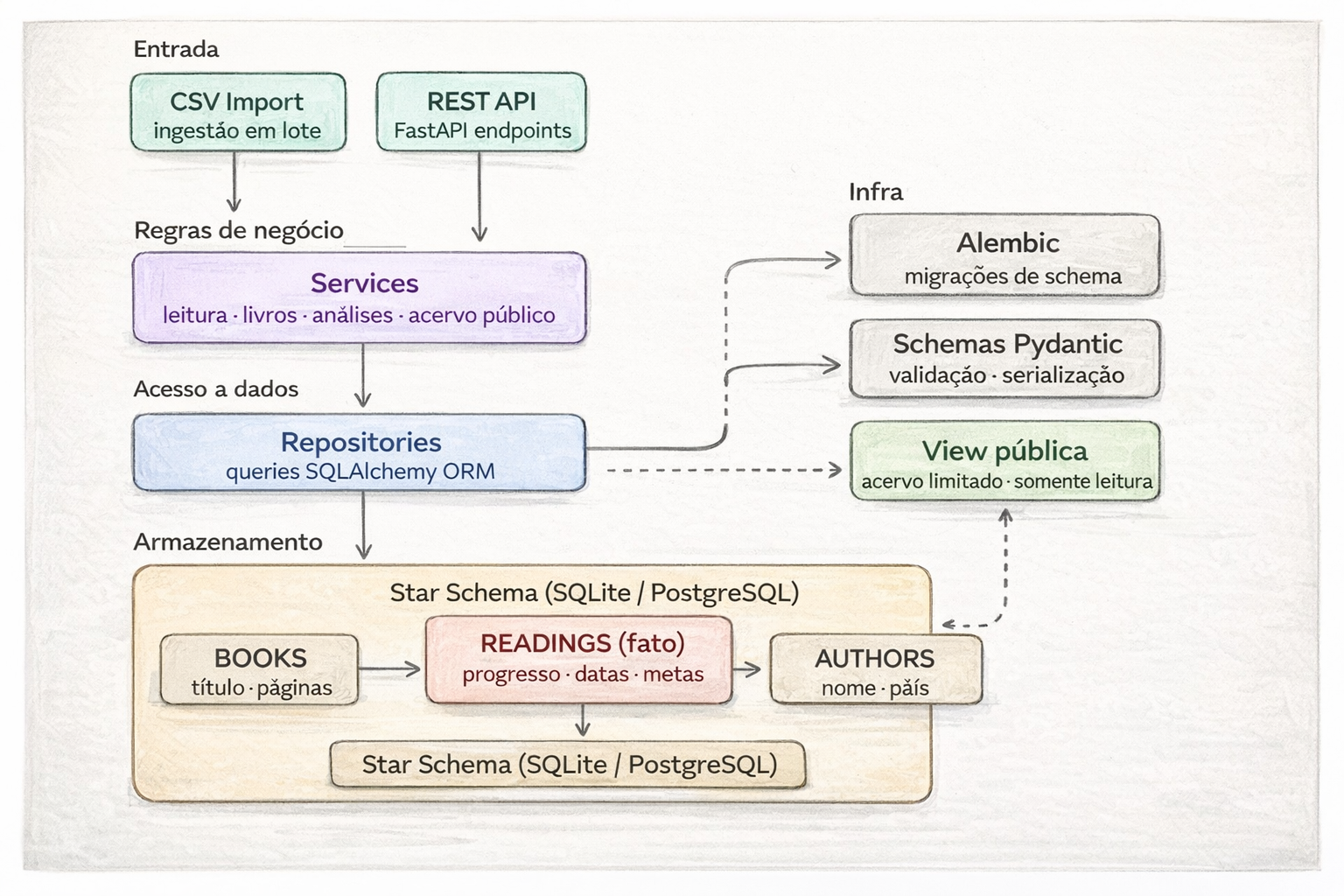
Tenho uma atuação bem completa no ciclo de dados: ingestão de fontes heterogêneas, mensageria, modelagem relacional e não relacional, construção de Data Warehouses em cloud e desenvolvimento de APIs para consumo de dados. Mais recentemente, venho me aprofundando em LLMs, RAG e embeddings para classificação e extração de informação em dados não estruturados.
No dia a dia, meu foco está em construir pipelines que sejam observáveis, resilientes e, principalmente, úteis para quem realmente vai consumir esses dados.
Certificações


Hard Skills
Linguagens & Processamento
Data Processing & Orchestration
Data Storage & Databases
Streaming & Messaging
Cloud & Data Platforms
Data Engineering Practices
- ETL/ELT Pipelines
- Data Modeling (Dimensional / Lakehouse)
- Data Quality & Validation
- Batch & Incremental Processing
- API Integration (REST)
- Query Optimization
- Medallion Architecture
- Web Scraping & Data Ingestion